Synthetic Resampling Strategies
Synthetic resampling strategies and machine learning for digital soil mapping in Iran
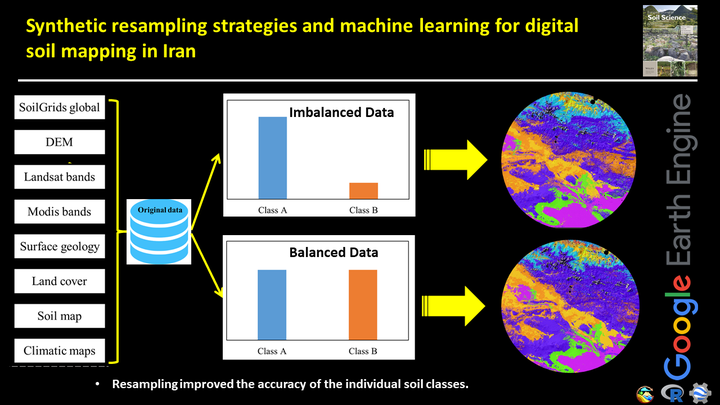
Table of Contents
Video Abstract
Motivation
Most of the common ML algorithms consider balanced training sets, that is, datasets where all classes are approximately represented equally. Because these algorithms treat all misclassifications equally, they have a bias towards classes with many instances, which often results in false accuracy estimates and the misclassification or neglect of classes with only a few instances. This is known as the class imbalance problem in ML. In this respect, datasets that do not follow this criterion are called imbalanced data. Most soil class datasets are therefore imbalanced data. We analysed and discussed the influence of the resampled balanced datasets as well as the prediction accuracies. Our main objective is to apply and test ML algorithms and resampling techniques for imbalanced legacy soil information in DSM.
Methods
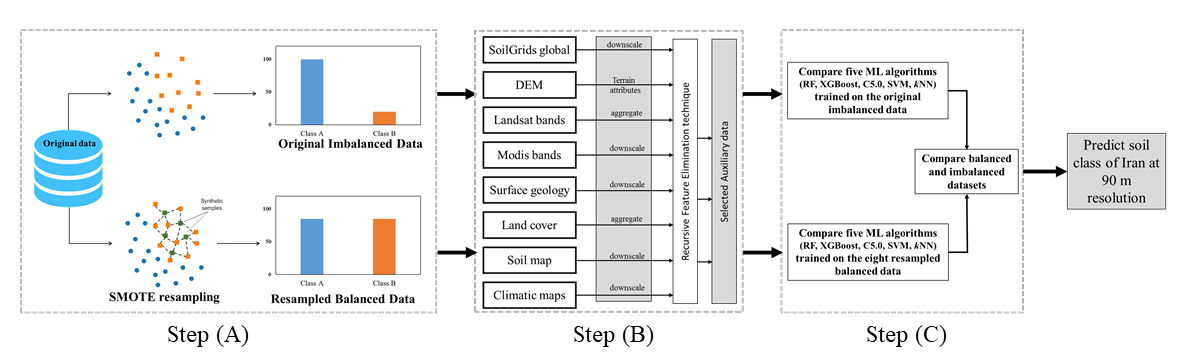
We tested five ML algorithms on eight resampled balanced datasets generated from the original imbalanced dataset to compare the influence on different algorithms. This work was conducted in three main steps: (a) preprocessing of soil datasets, (b) acquisition of covariates and (c) calibrating of ML algorithms.
Resampled balanced datasets
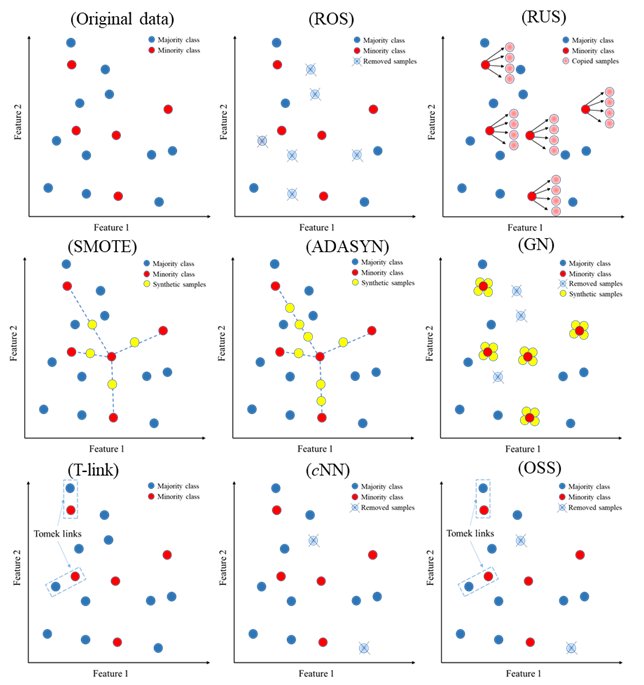
We used and tested eight resampling techniques (random under- and over-sampling, synthetic minority oversampling, adaptive synthetic sampling, the introduction of Gaussian Noise, Tomek link, condensed nearest neighbours and onesided selection method).
Accuracy assessment
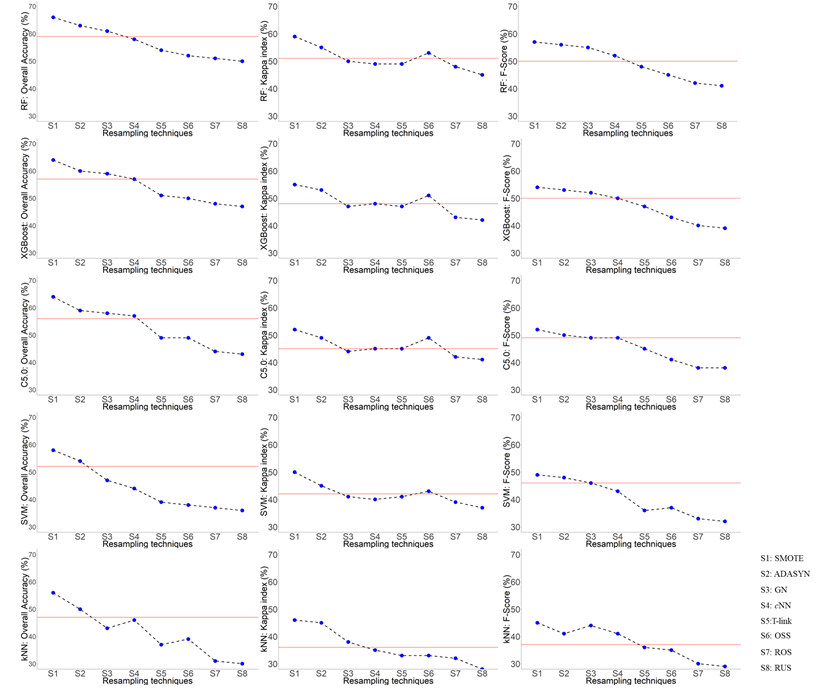
Balancing the dataset improved the prediction power of ML algorithms, compared to the original imbalanced data. This is particularly true when the data are preprocessed using the SMOTE resampling technique, which is better than any other resampling techniques and independent of the ML algorithm.
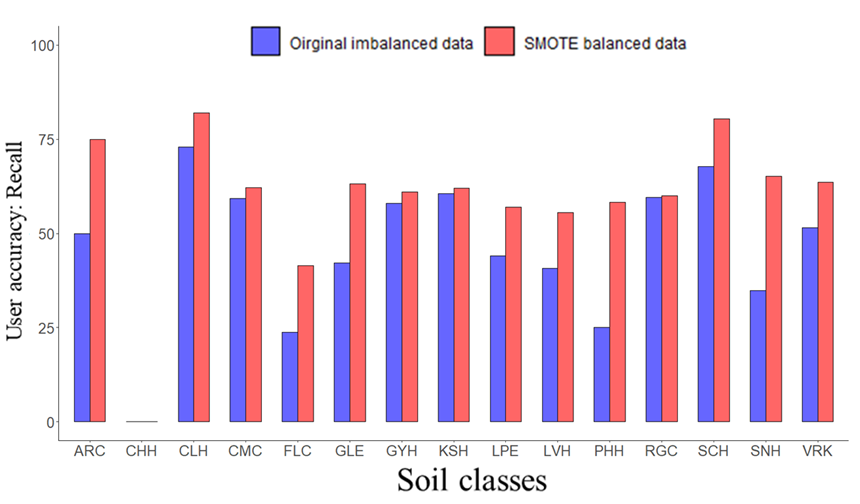
We should consider that the main purpose of resampling techniques is not improving the overall accuracy of models but enhancing the accuracy of each soil class, particularly minority soil classes. To test this assumption, we compared the recall values of each soil class obtained by the RF model trained on the original imbalanced dataset with those obtained by the RF trained on the SMOTE resampled balanced dataset. From the plot it is possible to get a sense that the SMOTE resampling technique improves the accuracy of most of the soil classes, compared to the original dataset.
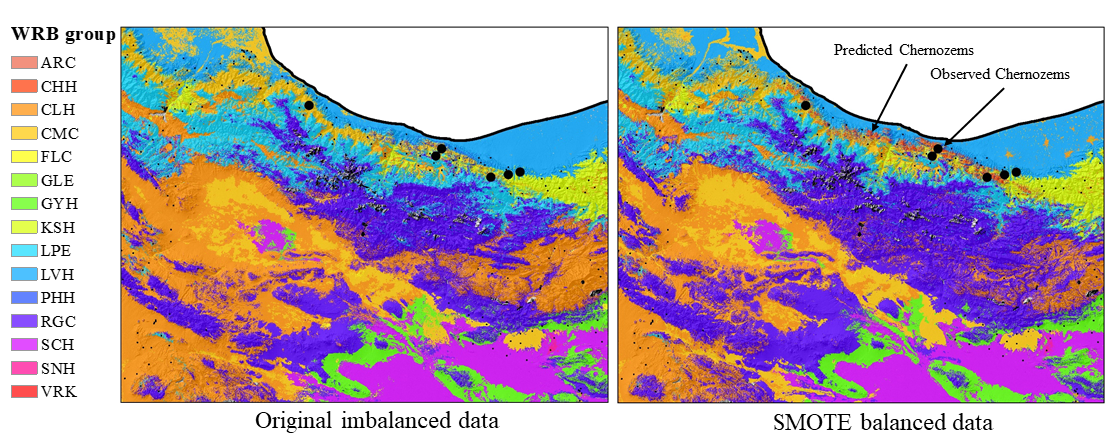
Spatial distribution of soils
we showed the differences between two maps generated by RF models (original data and SMOTE). As seen, the general spatial distribution of soil classes is similar. This is particularly true for the majority soil classes (e.g., Calcisols, Regosols and Cambisols); however, there are some differences in the areas predicted as Chernozems (i.e., the minority soil classes). When the predicted soil classes compared with actual soil profiles was overlaid on the maps, we could conclude that the RF model trained on the SMOTE resampled data model was much more successful in DSM.
Conclusion
Resampling the original datasets, particularly with the SMOTE technique, increased OA, K-index and F-Score in comparison to the original dataset. These results clearly indicate that standard ML algorithms could be better trained by the balanced SMOTE resampled dataset than imbalanced legacy data from existing soil maps. This is vital in DSM studies because they mostly rely on such imbalanced soil legacy data, in which the application of ML algorithms can generate highly biased soil class maps.
Ruhollah Taghizadeh
Postdoc Researcher
My research interests include soil mapping, data science, and machine learning