Carbon Mapping
Artificial bee colony feature selection algorithm combined with machine learning algorithms to predict vertical and lateral distribution of soil organic matter in South Dakota, USA
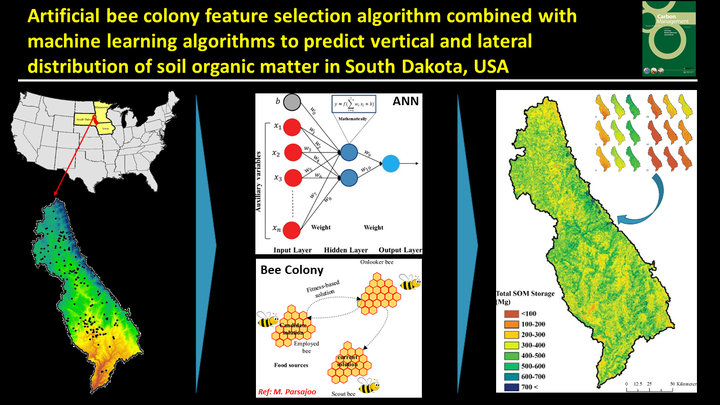
Table of Contents
Video Abstract
Motivation
The objectives of this study were to determine the optimal profile depth functions for modeling the vertical distribution of SOM in the agriculture-dominated Big Sioux River watershed by comparing power, exponential, and equal area splines; to evaluate and test the applicability of the optimal depth function and data mining techniques (SVR and ANN) to predict the vertical and lateral distributions of the SOM; to explore whether prediction improvements could be achieved using a feature selection technique (artificial bee colony algorithm) compared with SVR and ANN models fed with all auxiliary variables; and to investigate the effects of different land uses on three-dimensional distribution of SOM density and total SOM in the study watershed.
Study area
The Big Sioux River (BSR) watershed covers an area of 21,033 km2 and is located in the eastern part of South Dakota, USA. The average annual temperature is 7.6 °C with minimum and maximum values of 7.3 and 22.7 °C during January and July months, respectively.

Depth functions
The 200 soil samples in the BSR watershed were downloaded from Soil Survey Geographic Data (SSURGO). To standardize soil depths, the three most common depth functions (i.e. power, logarithmic and spline functions) were fitted to the measured data and SOM data was then derived with 0–0.05, 0.05–0.15, 0.15–0.30, 0.30–0.60, 0.60–1.00 and 1.00–2.00 m as the standard depths for digital soil mapping studies. The highest accuracy was achieved by the equal-area quadratic splines.

Artificial bee colony algorithm
In the ABC algorithm, there are basically three different groups: employed bees, onlooker bees and scout bees. The numbers of employed and onlooker bees in this algorithm are equal to the number of solutions in the population. The position of a food source represents a possible solution to the optimization of a problem (i.e. feature selection), and the nectar amount of a food source corresponds to the quality (i.e. auxiliary variables) of the associated solution. Employed bees find a food source, store the food quality information, and pass this information to onlooker bees. Based on the information from the employed bees, the onlooker bees choose a good-quality food source and exploit it. The scout bees randomly search for new food sources around the nest.
Support vector regression
Support vector machines (SVM) are supervised learning models based on the statistical learning theory, which were initially developed for the classification of linearly separable classes of objects by hyperplanes.

Artificial neural networks
ANNs are data mining methods that are commonly used as both regression and classification techniques. They are inspired by biological nervous systems, and particularly by research on the human brain. ANNs are developed and organized in such a way that they are able to learn from training data and therefore model complex processes without complex mathematical expressions.

Performance of the spatial models
Based on the outputs of error indices (ME, RMSE, R2, and nRMSE), both constructed models performed very well. Our results showed that the ANN had better performance than the SVR model in terms of SOM prediction at the standard depths. As visually evident in this figure, it is possible to get a sense that the best similarities between the actual and predicted values are for the first three depths, noticing the contour lines. However, the deteriorations in the results are depicted at the bottom of the soil profiles. The means that the best and worst performance of the ABC-based ANN model related to the prediction of SOM at the 0–0.05 and 1–2 m depths, respectively.

Spatial prediction of SOM
ABC-based ANN, the best data mining technique, was used for the SOM mapping.


Conclusion
The results demonstrate that SVR and ANN models generally performed well. The mean R2 values suggest that SVR and ANN models can explain approximately 50 and 57% of the total SOM variability, respectively. However, the predictive power of both models increased when the ABC feature-selection algorithm was applied. In aggregate, ABC-based ANN models showed much greater efficiency than the other models (SVR, ABC-based SVR and ANN) in predicting SOM contents for all standard depths.
Ruhollah Taghizadeh
Postdoc Researcher
My research interests include soil mapping, data science, and machine learning