Super Learning
Enhancing the accuracy of machine learning models using the super learner technique in digital soil mapping
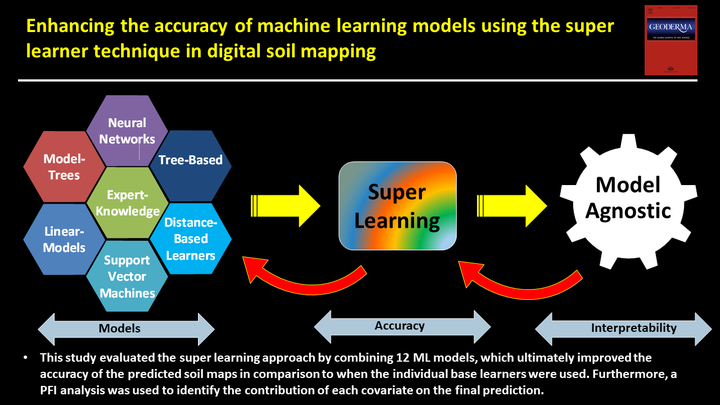
Table of Contents
Video Abstract
Motivation
To best of our knowledge, there has been limited studies that evaluated the super learner approach — especially in environments with highly saline soils. Furthermore, the contributions of the individual covariates within the overall predictive model have not always been explicitly quantified. Therefore, given the potential of super learner and model-agnostic interpretation tools, this study proposes their integration for the purposes of improving the accuracy of ML models and understanding the contribution of the environmental covariates on the final predictions.
Methods
Here, a super learner approach, which combines the predictions of base learners, is applied and a PFI analysis (i.e. model-agnostic interpretation approach) is used to rank the environmental covariates. Finally, we integrate the weight assigned to each ML base learner and the ranked covariates to understand the contribution of individual environmental covariates on the final prediction.
Super Learning
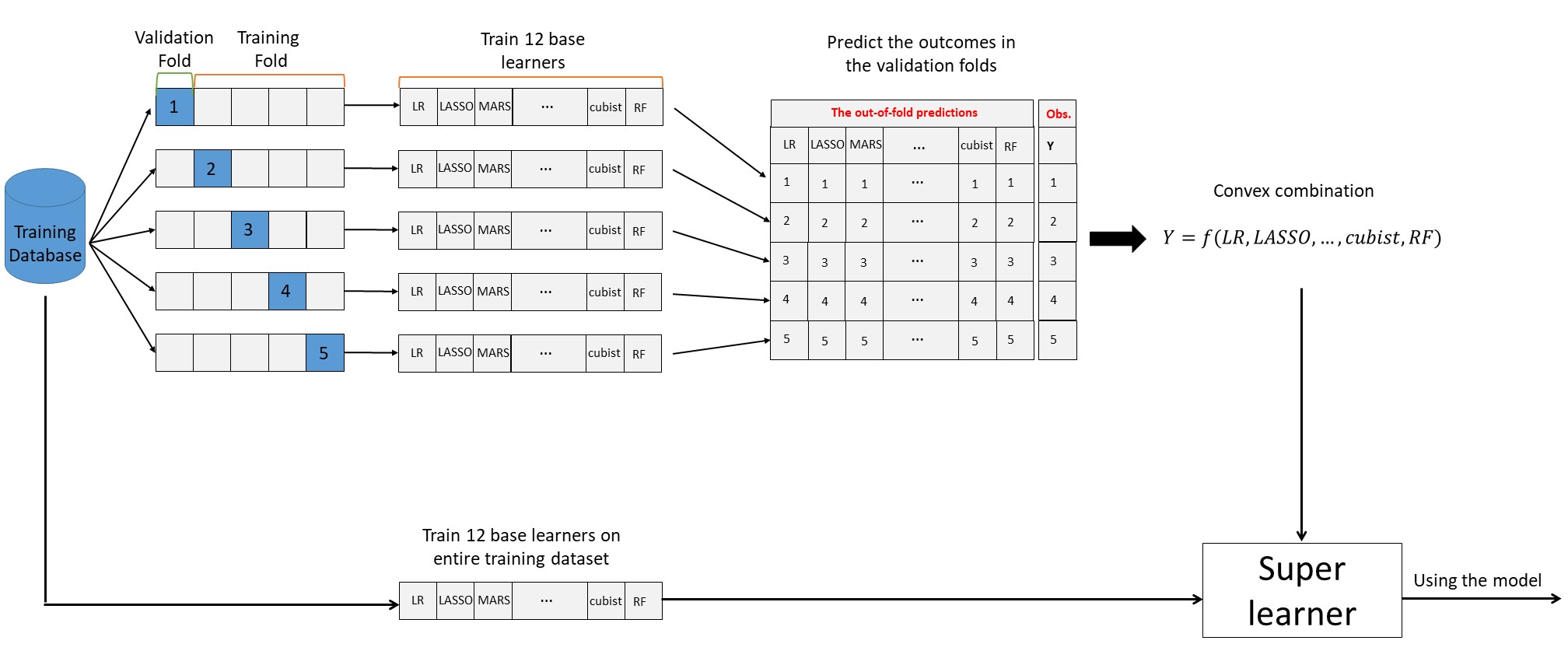
The super learner is a convex weighted combination of multiple ML algorithms (i.e. base learners) that combines all of the algorithms and model configurations, and makes a better prediction than any other individual algorithm (Van der Laan and Rose, 2011). Therefore, this technique not only describes the relationships of predictors with the modeling outcomes produced using penalized regression, but also has the potential to characterize the non-linear relationships and interaction by using spline algorithms or decision trees.
Permutation feature importance
The PFI method measures the change in prediction quality, as a function of increases in RMSE, through permutations of a single covariate vector. Here, a greater decrease in RMSE signals a greater importance of the covariate because the model relies more on the covariate when making predictions.
Accuracy assessment
By comparing the predictive performance of all models, the super learner had the highest accuracy. For instance, when predicting clay content, the best performing model was achieved by using the super learner, followed by AvEqC, RF, ANFIS, Cubist, XGBoost, ERT, ANN, SVR, MARS, kNN, GP, LASSO, and LR model.
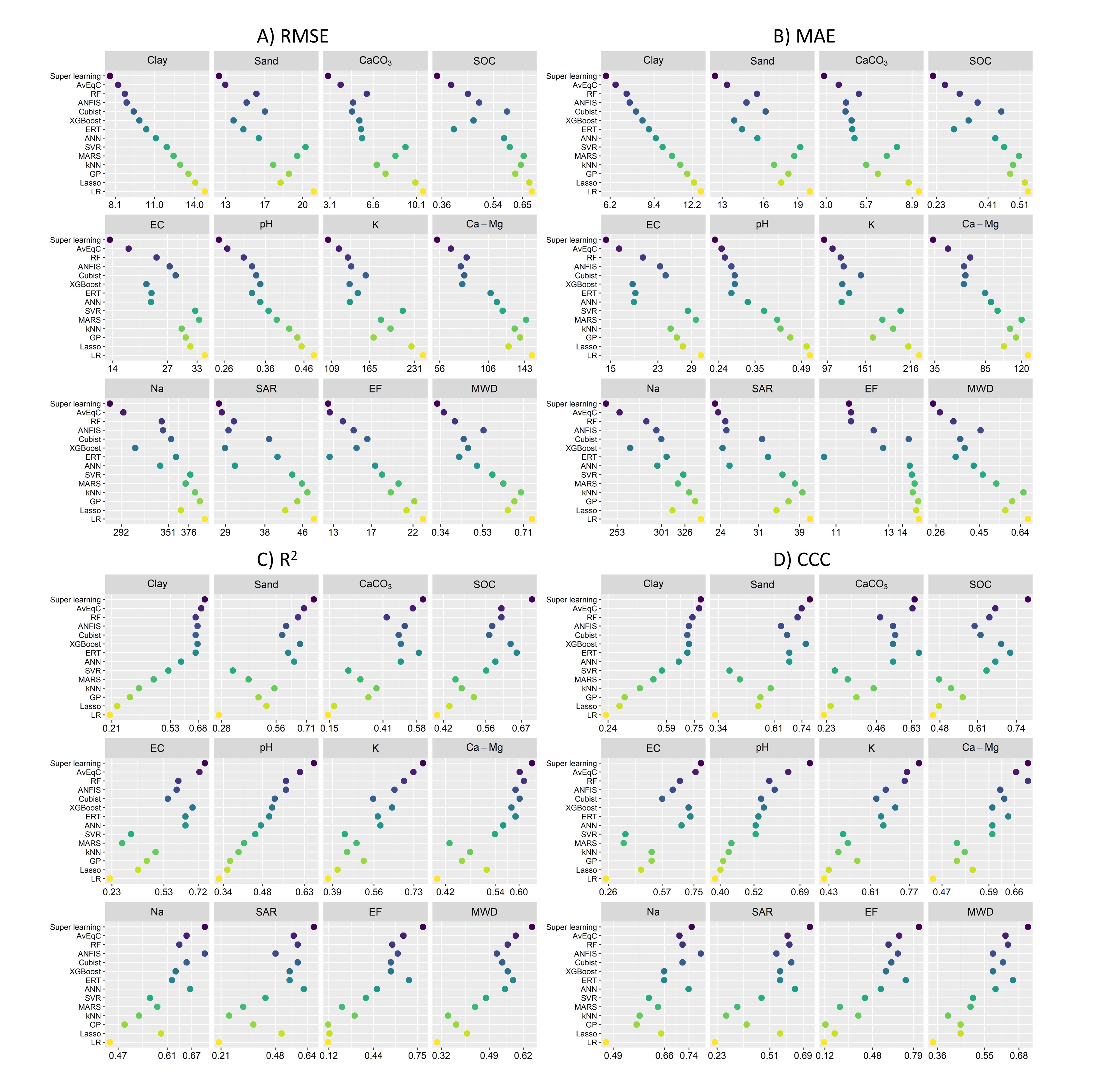
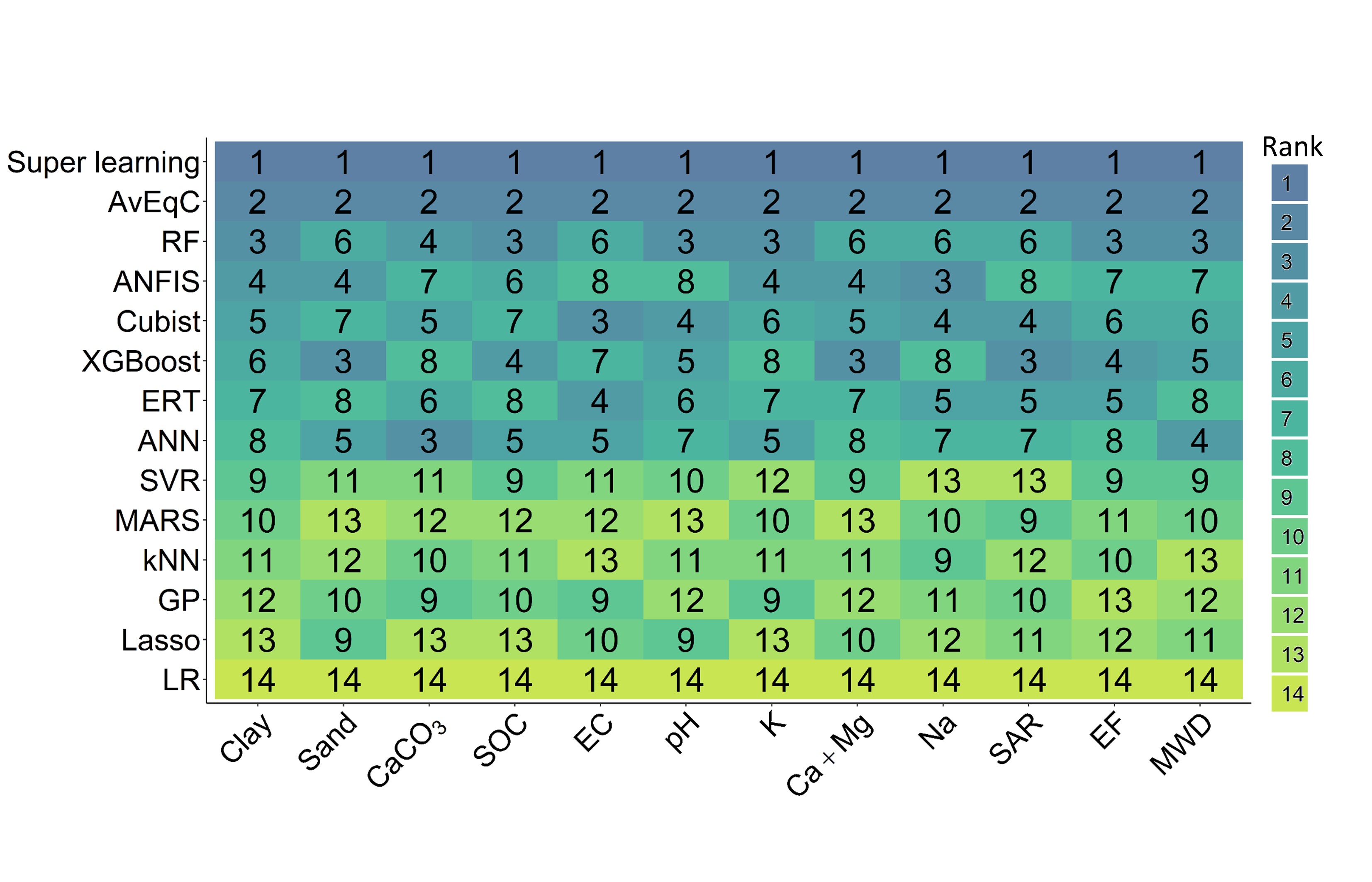
To obtain a more comprehensive view, we ranked the models for each soil property according to the RMSE (Fig. 5), where the numbers indicate the rankings of model effectiveness for each property. Again, the best performance was obtained using super learner and AvEqC, which were ranked first and second, respectively, for all soil properties. In contrast, LR models were consistently ranked the poorest—regardless of the soil property.
Importance of covariates
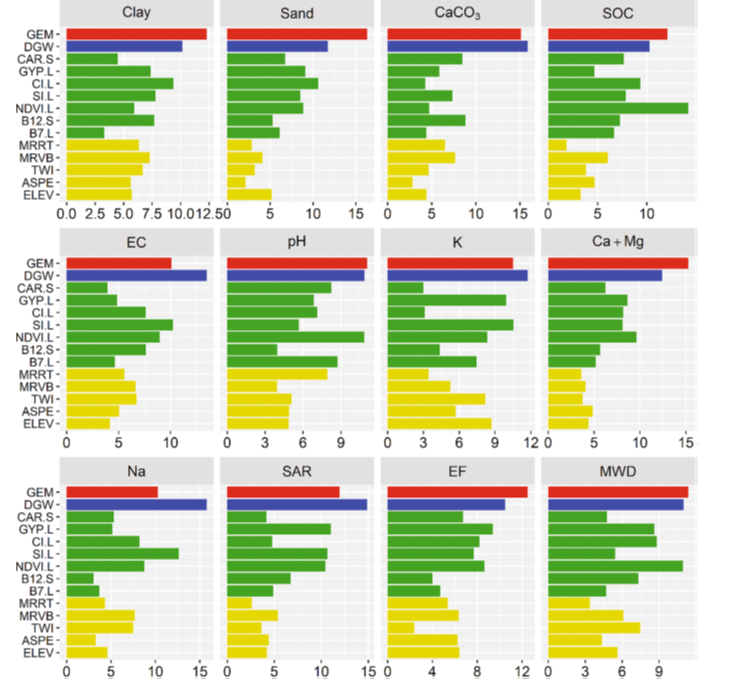
The relative importance of each covariate for predicting the soil properties is presented in Figure. As can be seen, the geomorphic map (GEM) had a strong influence on the prediction of all soil properties and was particularly effective in predicting soil properties, such as clay, sand, EF, and MWD. These soil properties are mostly affected by the nature of the sediments.
Conclusion
This study evaluated the super learning approach by combining 12 ML models, which ultimately improved the accuracy of the predicted soil maps in comparison to when the individual base learners were used. Furthermore, a PFI analysis was used to identify the contribution of each covariate on the final prediction.
Ruhollah Taghizadeh
Postdoc Researcher
My research interests include soil mapping, data science, and machine learning